

Quand l’intérêt collectif se heurte au coût individuel
Dans Curebot, le tagging est un geste quotidien qui semble anodin mais qui structure profondément l’expérience collective.
Lorsqu’un utilisateur qualifie une ressource, il s’investit pour choisir les termes, vérifier la cohérence sémantique avec les pratiques de l’organisation et maintenir une logique de tagging personnelle. Le coût est concentré sur lui.
Un tag bien choisi améliore la découvrabilité pour tous les utilisateurs futurs mais celui qui l’a posé voit son bénéfice distribué. Ce déséquilibre est amplifié par une asymétrie d’expertise.
Les veilleurs professionnels qui ont assimilés les taxonomies taguent abondamment. Les contributeurs occasionnels, les nouveaux arrivants, les métiers non spécialistes de la veille, les managers qui capitalisent ponctuellement hésitent à taguer. Une proportion significative des ressources reste alors sous-qualifiée, la recherche devient moins efficace et la valeur collective ne croît pas aussi vite que l’on pourrait l’espérer.
Notre objectif initial était de réduire le coût individuel du tagging.
Conceptualiser le tag comme signal transférable
Notre approche repose sur une idée simple. Un tag n’est pas seulement une étiquette descriptive. C’est un signal d’interprétation déposé par un utilisateur sur un contenu. Ce signal porte une information sémantique (de quoi parle la ressource) mais aussi une information sociale (comment un membre de la communauté a choisi de la qualifier)
Si deux ressources traitent du même sujet, les tags déposés sur l’une ont une forte probabilité d’être pertinents pour l’autre. La similarité de contenu justifie la transférabilité de ce signal.
Mais cette transférabilité ne doit pas être mécanique. Un tag isolé sur une seule ressource similaire peut relever d’une préférence idiosyncrasique, c’est-à-dire un choix subjectif plutôt qu’un standard. En revanche, quand plusieurs utilisateurs, indépendamment, apposent le même tag sur des ressources proches, ce tag devient un consensus implicite. C’est ce consensus qu’il faut capturer et proposer en priorité.
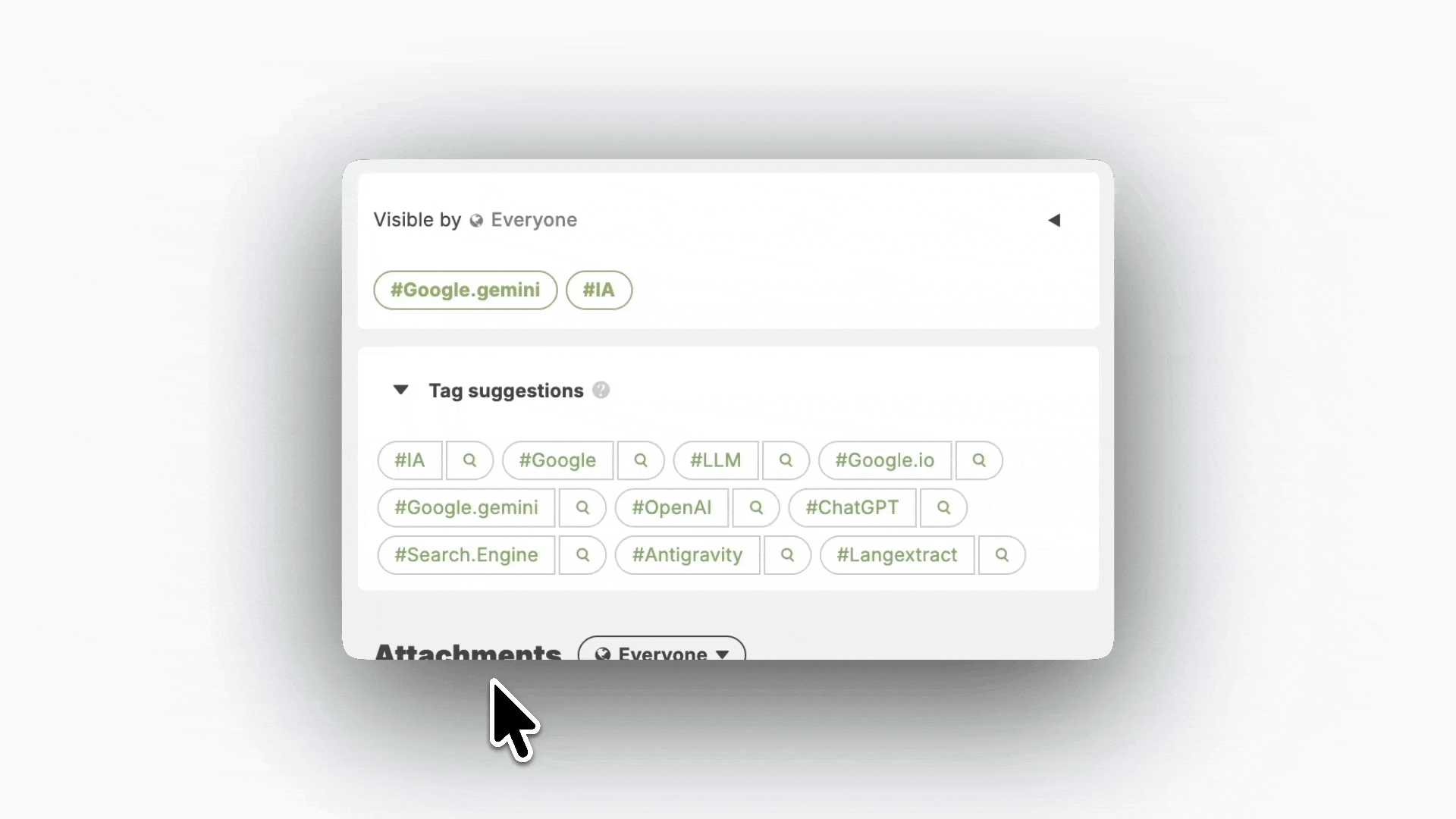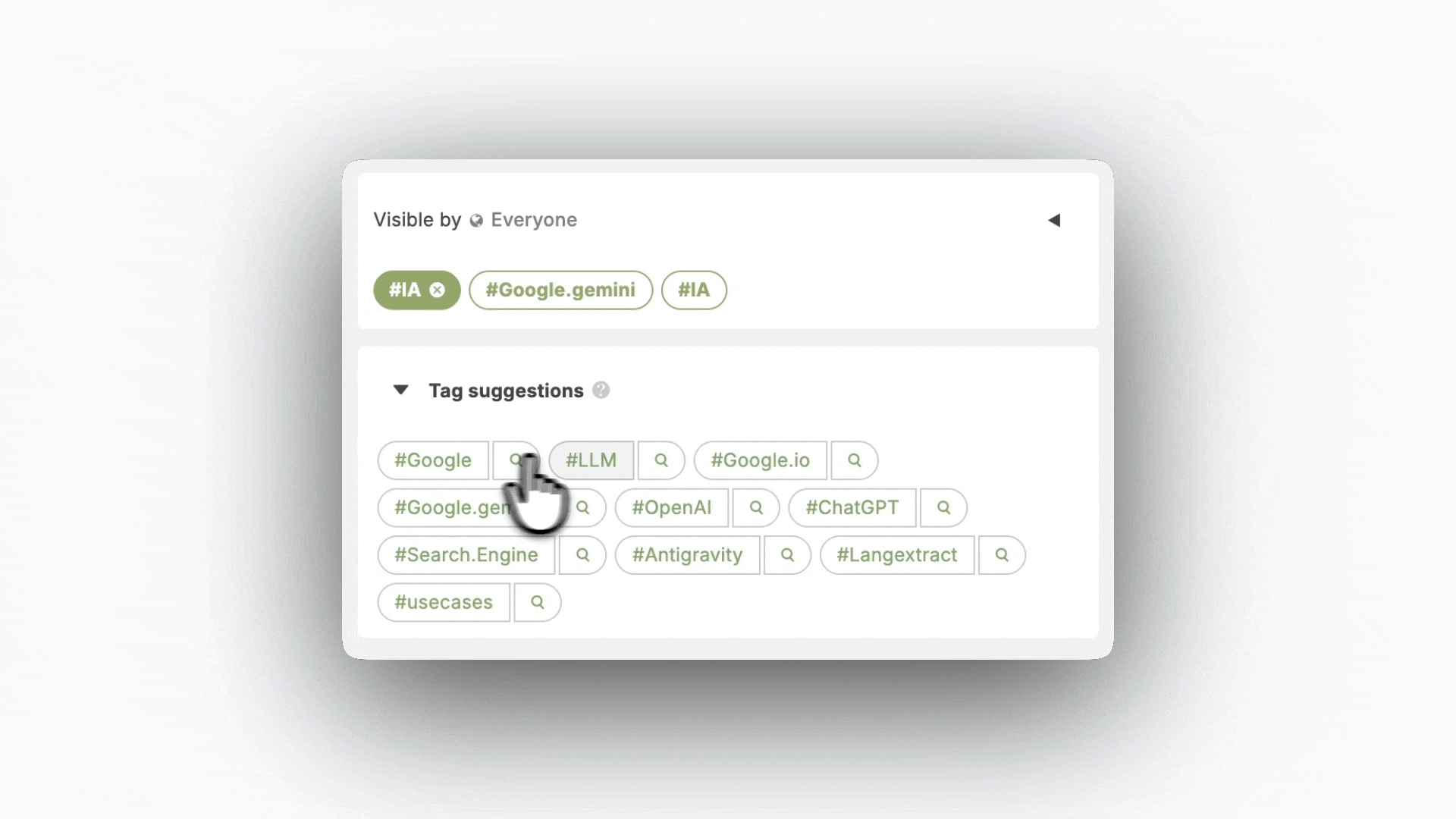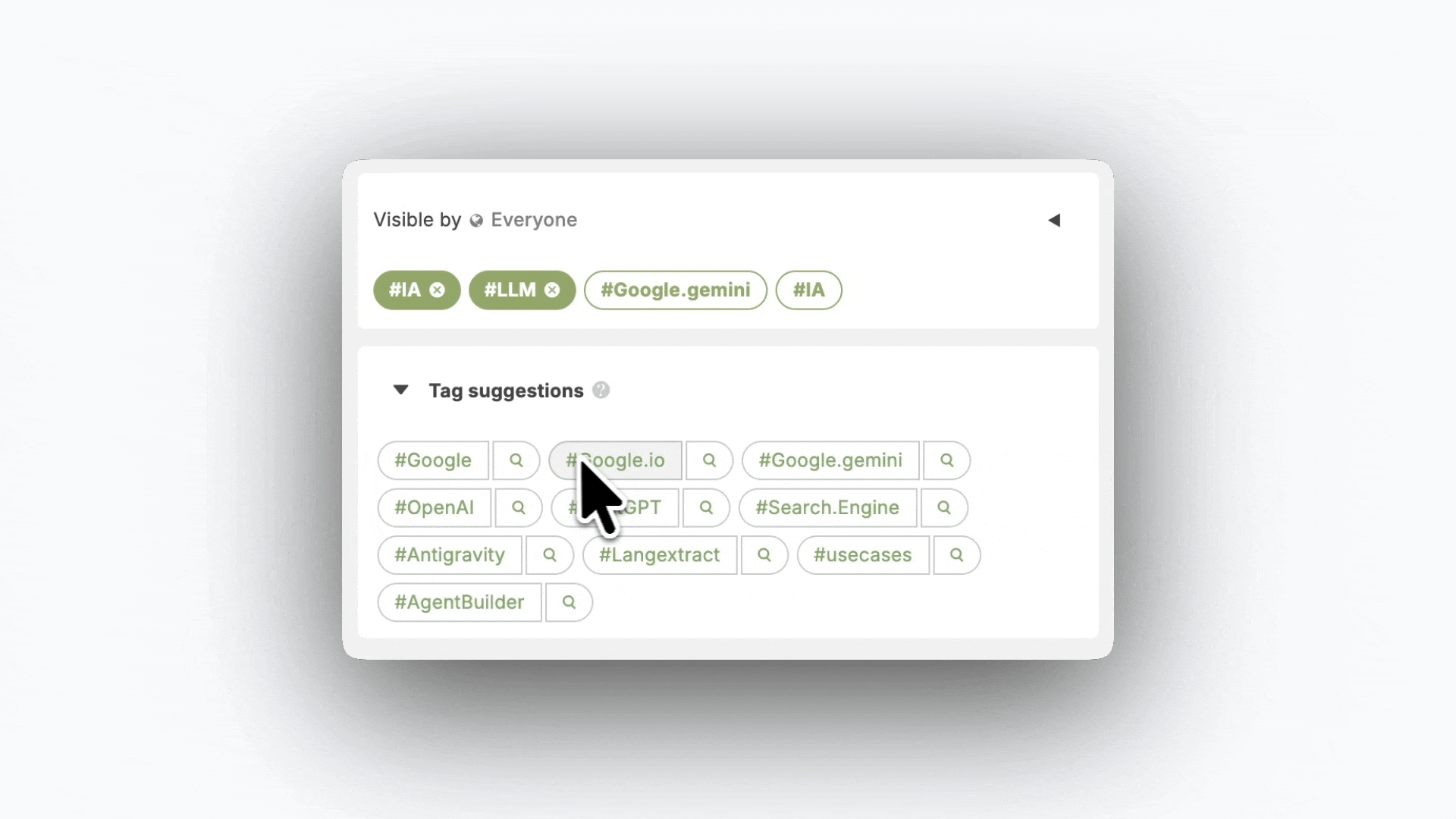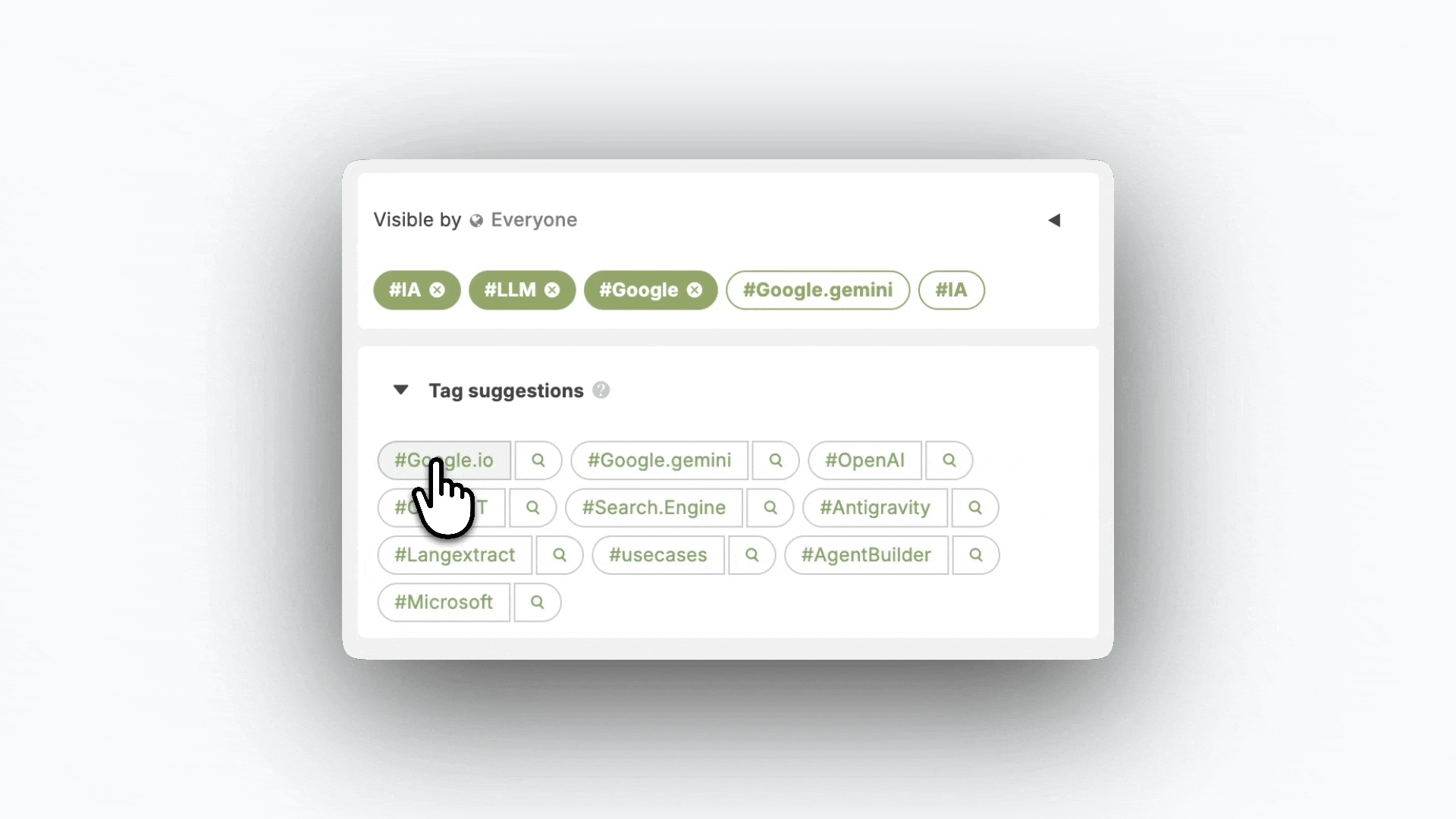
Notre objectif n’était donc pas simplement d’accélérer le tagging, mais de rendre l’ajout de tags à la fois plus efficient individuellement et plus productif collectivement. Il s’agissait de concevoir un mécanisme qui capte l’intelligence déjà présente dans la base de connaissances et la redistribuer au moment où elle est utile.
De l’algorithme de similarité au scoring
Calculer la similarité et identifier des ressources candidates
La première étape consiste à identifier, pour la ressource consultée, l’ensemble des ressources les plus similaires dans l’index du client. Le choix de N (le nombre de ressources similaires à considérer) est un paramètre important. Trop faible, il limite la diversité des tags suggérés et risque de ne pas capturer suffisamment de signal. Trop élevé, il introduit du bruit en incluant des ressources dont la proximité est trop faible pour justifier la transférabilité des tags. Après tests, nous avons fixé N à un seuil qui maximise le compromis entre couverture sémantique et pertinence.
Agréger les tags par score de pertinence
Une fois les N ressources similaires identifiées, nous récupérons l’ensemble des tags déposés sur chacune d’elles. Un même tag peut apparaître sur plusieurs ressources similaires, avec des degrés de proximité différents. Nous agrégeons ces occurrences pour produire un score de pertinence unique par tag.
Le score d’un tag est calculé comme la somme de ses apparitions sur les ressources similaires, où chaque apparition est pondérée par le score de similarité de l’article qui le porte. Concrètement, si un tag T apparaît sur k ressources parmi les N considérées, et que ces ressources ont des scores de similarité respectives s₁, s₂, ..., sₖ , alors :
Score(T) = s₁ + s₂ + … + sₖ
Cette formule présente plusieurs propriétés utiles.
- Favorise le consensus : un tag qui apparait fréquemment accumule du score, reflétant sa validation collective
- Favorise la proximité : un tag présent sur les ressources les plus similaires obtient un score plus élevé, garantissant la pertinence contextuelle.
- Pénalise le bruit : les tags rares ou présents uniquement sur des ressources peu similaires sont naturellement en bas de classement.
Filtrer et rafraîchir dynamiquement
Après agrégation, nous obtenons une liste de tags avec leurs scores respectifs. Nous présentons dans un premier temps les 10 tags les mieux classés. Ce nombre offre un équilibre entre richesse des suggestions et lisibilité de l’interface.
Ce filtrage à 10 suggestions est recalculé en temps réel. La liste est rafraichie dynamiquement à chaque interaction. Si l’utilisateur ajoute ou supprime un tag, la suggestion correspondante disparaît instantanément de la liste et la 11ème dans l’ordre de scoring prend sa place. Ce mécanisme maintient une liste constante de 10 suggestions tant qu’il reste des tags candidats.
Respecter les périmètres de visibilité
Un point critique concerne la confidentialité et la gestion des droits. Dans Curebot, les tags peuvent être déposés avec différents périmètres de visibilité : public, restreint à un groupe ou privé. Nous exploitons ce principe pour les suggestions. Quand l’utilisateur clique sur une suggestion pour l’ajouter, Curebot applique le périmètre de visibilité sélectionné. Périmètre qui peut différer de celui d’origine.
En complément, nous avons choisi une règle stricte mais évidente. L’algorithme ne considère dans le calcul que les tags que l’utilisateur a le droit de voir. Cette règle garantit que les suggestions respectent les niveaux de confidentialité définis par les utilisateurs.
Les effets sur la dynamique d’engagement
Cette nouveauté génère trois dynamiques collectives et transforment progressivement la qualité de l’écosystème informationnel de l’organisation
Convergence sans normalisation imposée
Dans une plateforme de veille traditionnelle, les utilisateurs développent des pratiques de tagging hétérogènes. Certains privilégient des tags génériques, d’autres des tags ultra-spécifiques, d’autres encore inventent des terminologies personnelles. Cette hétérogénéité fragmente la base de connaissances et complique la découverte transversale.
Deux approches classiques existent pour harmoniser les pratiques de tagging.
- Imposer une taxonomie fermée avec une liste de tags prédéfinis, ce qui fige le vocabulaire et est profondément anti-contributif et anti-collaboratif.
- Laisser une liberté totale du tagging, sans aucun moyen de ré-exploiter la diversité des qualifications.
Curebot trace une troisième voie. Notre système unique de recherche intelligente permet d’ores et déjà de remobiliser les variances de tagging les plus nombreuses et les plus complexes. Aujourd’hui, les suggestions de tags poursuivent cette ambition de guider sans contraindre. Elles rendent visibles les termes qui fonctionnent, ceux que la communauté utilise vraiment. Les utilisateurs convergent naturellement vers ce vocabulaire partagé. Ils conservent la liberté de créer de nouveaux tags si l’existant ne convient pas.
Activation des contributeurs occasionnels
Avec les suggestions, un nouvel arrivant peut qualifier une ressource en quelques clics avec le vocabulaire de son organisation. Ce faisant, il contribue sans effort à enrichir la base de tags, ce qui améliore les suggestions futures pour tous. Il se crée ainsi une boucle d’amélioration continue. Cela renforce l’engagement et crée un sentiment d’appartenance à un collectif productif. Les utilisateurs ne sont plus des consommateurs passifs de contenu. Ils deviennent acteurs de la structuration de la connaissance de l’organisation.
Boucle de renforcement
Le mécanisme s’auto-alimente. Plus la base de tags s’enrichit, meilleures sont les suggestions. Meilleures sont les suggestions, plus d’utilisateurs taguent. Plus d’utilisateurs taguent, plus la pertinence de l’algorithme s’améliore. Cette boucle ne nécessite ni formation, ni comité de normalisation, ni contrôle qualité centralisé. Elle émerge de l’architecture. Les bonnes pratiques se diffusent parce qu’elles deviennent visibles et reproductibles.
La collaboration comme infrastructure, pas comme option
Les suggestions de tags illustrent une conviction de design qui structure notre approche produit. La collaboration ne doit pas être une couche superficielle ajoutée après coup. Elle doit être l’infrastructure sur laquelle reposent les fonctionnalités.
Trop souvent, les plateformes dites « collaboratives » se contentent d’ajouter un bouton “partager” ou un fil de commentaires à des outils conçus pour un usage individuel. Le résultat est une collaboration artificielle, peu utilisée, peu utile, qui n’apporte qu’une valeur marginale.
Nous aurions pu concevoir les suggestions comme une aide isolée, un raccourci ergonomique, mais notre approche est inverse. Concrètement, cela signifie concevoir chaque fonctionnalité en se posant deux questions.
- Comment peut-elle tirer parti de l’intelligence collective déjà présente dans la plateforme ?
- Comment peut-elle contribuer à enrichir cette intelligence pour les utilisateurs futurs ?
Les suggestions de tags répondent aux deux.
- Elles extraient de la valeur des qualifications passées.
- Elles transforment chaque nouveau tag en contribution remise au collectif.
L’utilisateur n’a pas besoin d’en avoir conscience. La collaboration est une conséquence de l’usage, pas un objectif séparé qu’il faudrait inciter artificiellement.

{kind=link}
{kind=link}
{kind=link}